library(plotly); library(magrittr)library(tidyquant)# Use tidyquant to get the dataINTC <-tq_get("INTC")# Slice off the most recent 90 daysINTC.tail.90<-tail(INTC, 90)INTC.tail <- INTC.tail.90# Create a counter of daysINTC.tail$ID <-seq.int(nrow(INTC.tail))# Round the prices to 2 digitsINTC.tail %<>%mutate(close =round(close, digits=2))
Now we want a function to create the dataset for each stage of the animation. There are a few ways to do this but most involve writing a function to create them. This example function comes from the plotly documents.
Code
# This is in the example for plotly paths# First a supporting function: getLevels takes input xgetLevels <-function (x) {# if x is a factorif (is.factor(x)) # grab the levels of xlevels(x)# if x is not a factor, sort unique values of xelsesort(unique(x))}# Two inputs, the data and the variable to form the splits along the x-axisaccumulate_by <-function(dat, var) {# This handles linking variables to their environment var <- lazyeval::f_eval(var, dat)# get the levels of the given variable using the function above lvls <-getLevels(var)# use lapply, tidy would use map to iterate over the levels in `lvls` and column bind the data with frame denotes by lvls[[x]] dats <-lapply(seq_along(lvls), function(x) {cbind(dat[var %in% lvls[seq(1, x)], ], frame = lvls[[x]]) })# bind the rows together dplyr::bind_rows(dats)}# Invoke the function on our ID variableINTC.tail <- INTC.tail %>%accumulate_by(~ID)# Create a figure of ID and close for each frame value using plotly's version of a line plot: type:scatter-mode:lines# The rest is standard plotlyfig <- INTC.tail %>%plot_ly(x =~ID, y =~close, frame =~frame,type ='scatter', mode ='lines', # This is short for fill to zero on the y-axisfill ='tozeroy',fillcolor='rgba(73, 26, 201, 0.5)',line =list(color ='rgb(73, 26, 201)'),text =~paste("Date: ", date, "<br>Close: $", close), hoverinfo ='text')# Add the layout; one title and two axes# I also mess with the margin to keep the figure from being cut off.fig <- fig %>%layout(title ="Intel Stock Closing Price: Last 90 Days",yaxis =list(title ="Close", range =c(0,50), zeroline = F,tickprefix ="$" ),xaxis =list(title ="Day", range =c(0,90), zeroline = F, showgrid = F ),margin =list(t=120) # adjust the plot margin to avoid cutting off letters) # Animate the figure with 100 framesfig <- fig %>%animation_opts(frame =100, # transition time 100 mstransition =0, # duration of smooth transition in msredraw =FALSE# redraw the plot at each transition?)fig <- fig %>%animation_slider(currentvalue =list(prefix ="Day " ))fig
An easier plotly for these data because they are OHLC
To link the data selection and the visualization, I need one line of code necessary to share the data.
Code
# Get bscols onto rows with widths# https://stackoverflow.com/questions/72064781/in-package-crosstalk-are-there-have-function-bsrows-and-rowscols-mixedlibrary(crosstalk); library(plotly)shared <- SharedData$new(HR.Data.Selection)bscols(widths =c(12, 12),plot_ly(shared, x =~Mean, y=~SD, type ="scatter"),datatable(shared))
A #tidyTuesday on pizza shop ratings data. The data come from a variety of sources; it is price, ratings, and similar data for pizza restaurants. The actual contents vary depending on the data source. I will begin by loading the data and summarizing what data seem to be available so that we can figure out what we can do with it. Let’s see what we have; NB: there are three datasets, I chose one.
name address city country
Length:10000 Length:10000 Length:10000 Length:10000
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
province latitude longitude categories
Length:10000 Min. :21.42 Min. :-157.80 Length:10000
Class :character 1st Qu.:34.42 1st Qu.:-104.80 Class :character
Mode :character Median :40.12 Median : -82.91 Mode :character
Mean :38.37 Mean : -90.06
3rd Qu.:40.91 3rd Qu.: -75.19
Max. :64.85 Max. : -71.95
price_range_min price_range_max
Min. : 0.000 Min. : 7.00
1st Qu.: 0.000 1st Qu.:25.00
Median : 0.000 Median :25.00
Mean : 4.655 Mean :27.76
3rd Qu.: 0.000 3rd Qu.:25.00
Max. :50.000 Max. :55.00
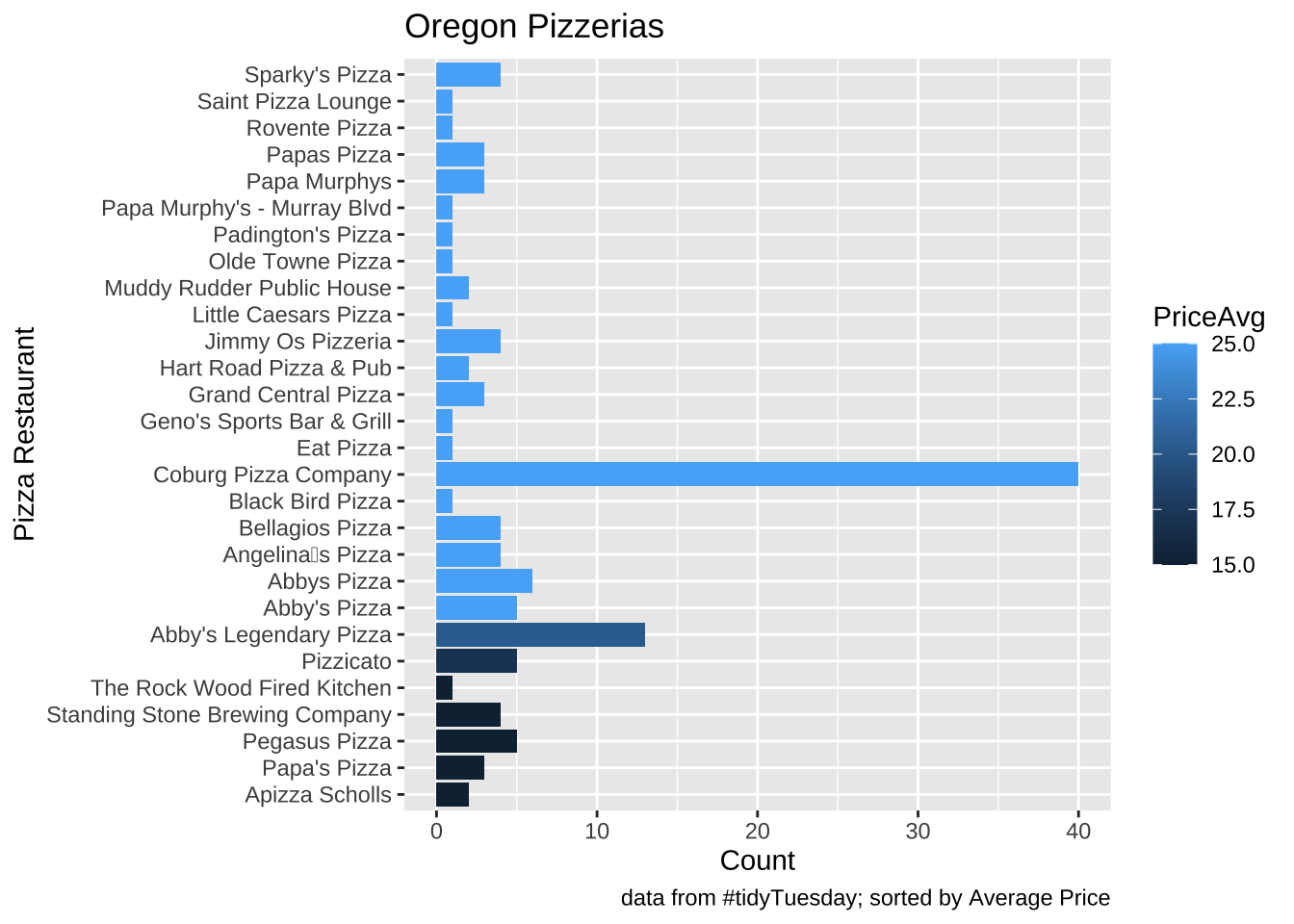
I will use this data; it contains some Oregon pizzarias.
Code
pizza_datafiniti %>%filter(province=="OR")
# A tibble: 122 × 10
name address city country province latitude longitude categories
<chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <chr>
1 Coburg Pizza Co… 1710 C… Spri… US OR 44.1 -123. Restauran…
2 Coburg Pizza Co… 1710 C… Spri… US OR 44.1 -123. Restauran…
3 Coburg Pizza Co… 1710 C… Spri… US OR 44.1 -123. Restauran…
4 Coburg Pizza Co… 1710 C… Spri… US OR 44.1 -123. Restauran…
5 Coburg Pizza Co… 1710 C… Spri… US OR 44.1 -123. Restauran…
6 Coburg Pizza Co… 1710 C… Spri… US OR 44.1 -123. Restauran…
7 Coburg Pizza Co… 1710 C… Spri… US OR 44.1 -123. Restauran…
8 Coburg Pizza Co… 1710 C… Spri… US OR 44.1 -123. Restauran…
9 Coburg Pizza Co… 1710 C… Spri… US OR 44.1 -123. Restauran…
10 Coburg Pizza Co… 1710 C… Spri… US OR 44.1 -123. Restauran…
# ℹ 112 more rows
# ℹ 2 more variables: price_range_min <dbl>, price_range_max <dbl>
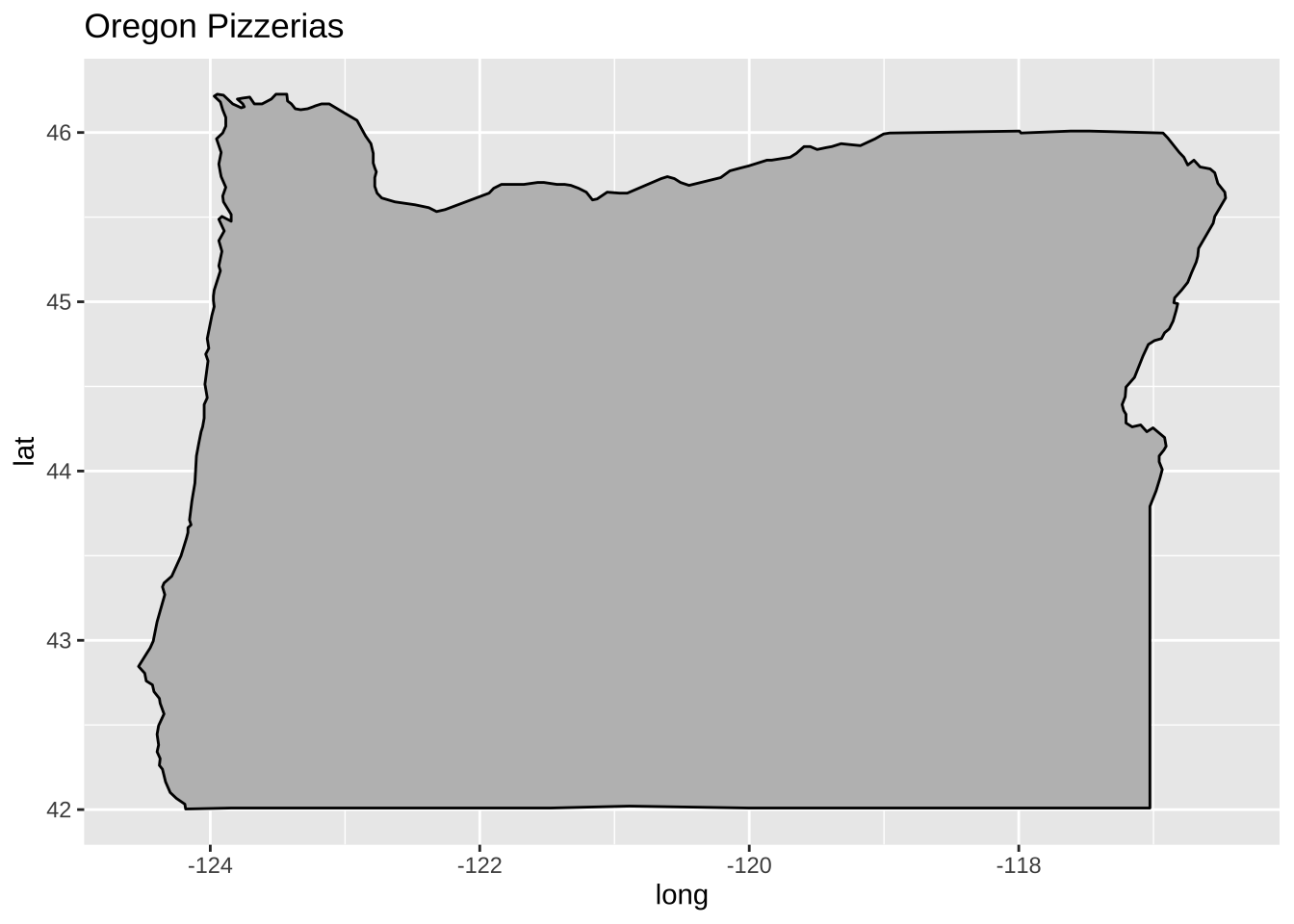
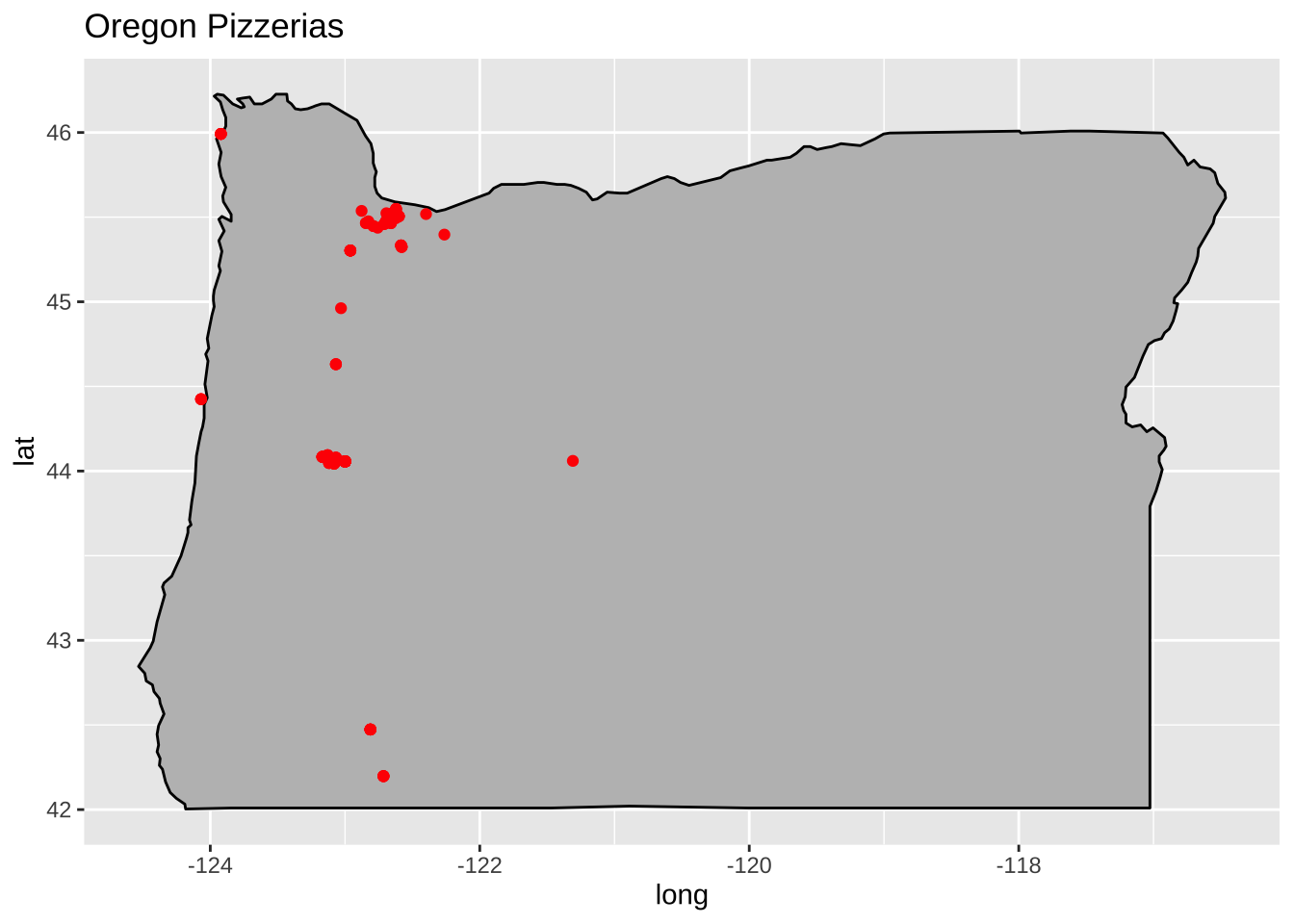
For the first plot, let me show what is going on in Oregon.
pizzaData$group <-44states <-map_data("state")OR.df <-subset(states, region =="oregon")OR_base <-ggplot(data = OR.df, mapping =aes(x = long, y = lat, group = group)) +geom_polygon(color ="black", fill ="gray") +labs(title="Oregon Pizzerias")OR_base
Ted Laderas [@laderast on Twitter] wrote a function to present the ten most expensive items in a category for the items dataset. You can find his repo for this here.. I will change rows 3 and 9. Line 3 adds the new argument to the function and line 9 carries the variable defined in the argument into top_n.